Search
how to use
如何使用
Follow the steps below to enable search:Follow the steps below to enable search:
- Go to the
indexespage to select a Search index and clickSave. - After the index is saved, click
Build indexesto build the index. - Now you can search for files by click the search block on the top right corner of the page or by using the shortcut
Ctrl + K. ❗ If you do not follow the above prompts, the prompt will be opened: Search Not available
按照以下步骤开启搜索:按照以下步骤开启搜索:
- 转到
索引页,选择一个搜索索引,并单击保存; - 保存索引后,单击
构建索引来构建索引; - 现在你可以通过点击页面右上角的搜索块或使用快捷键
Ctrl + K来搜索文件。 ❗ 若不按照上述提示开启会提示:Search not available
Difference between different search indexes
不同搜索索引之间的差异
database: Search by database, which is using the existing data.db. It will create a new table, record the parent directory, name, and size of every object, but the search does not split words which means that match whether the keywords you enter appear in the name of object. In general, if you don’t have a specific search requirement, we recommend you choose it.database (non-full-text search): The full-text search mode is used above, but full-text search will have some strange problems when using MySQL database as an Alist database, which has not been resolved yet, so if your Alist database Change to MySQL, and your Alist version≥3.9.1It is recommended that you use this to build an index, although it is slower than full-text search and the gap is not very big, but it will not search for strange files , it’s more secure. After the future version is repaired, we will inform you to use the new full-text search to build the index. If you are using sqlite3, you can use whichever you like.bleve: An open source full-text search engine. It will split the words in the name of object and search for the keywords you enter. But its search results may be so strange that you can’t get the results you want, and it will take up more resources.- sqlite3 is easy to trigger
database is lockedlock library cannot write files- Solution to
database is locked:- It’s because the database is building the index. If you are still in the building process, please wait patiently.
- If the index has been completed, it is caused by turning on Automatically update the index. Please turn off Automatically update the index. If the problem still occurs, please close and restart OpenList.
- Or switch the database to MySQL
- Solution to
meilisearch: I haven’t experienced it in depth yet and I don’t know much about the specific differences. It’s for professionals to use or you can check it yourself. View PR link , the only thing I know is that you have to build it yourself to use it. It supports many methods, but there is no daemon and other lazy operations, and it does not support the system It relies on Linux systems lower thanGLIBC_2.27If it is built on this machine, it will be automatically recognized. If it is another device, you can modify the meilisearch field content of the configuration file.- Daemon:If you want to use it, you can create a new daemon process in the same way as manually starting OpenList.
- Download Url:https://github.com/meilisearch/meilisearch/releases -
meilisearchDocs Url:https://www.meilisearch.com/docs/learn/getting_started/installation - Reference Links:https://github.com/AlistGo/alist/discussions/6830
The following table could help you understand the difference between the two search indexes quickly:database(full text search) Database (non-full-text search) bleve meilisearch Search results Can’t find it in Chinese More accurate than full-text search, you can search Chinese Fuzzy match ❓ Search speed Fast,see above for advantages and disadvantages Slower than full-text search, see above for advantages and disadvantages Fast ❓ Specify folder search Yes Yes No ❓ Disk usage Low Low High ❓ Auto incremental update Yes Yes No ❓ WARNING注意
If you are using MySQL as the database, it is recommended to use
non-full-text search(strongly recommended)Non-full-text searchAlthough it is not as fast as full-text search, it is not much slower. If you insist on using full-text search, you may have to sacrifice the inability to search Chinese If you use ==sqlite== as the database, there is no full-text search, you can choose any database~ Full-text search: It will not search in the text of all files, don’t get it wrong.
数据库:按数据库搜索,它使用现有的 data.db。它将创建一个新表,记录父目录、名称和每个对象的大小,但搜索不拆分单词,这意味着匹配您输入的关键字是否出现在对象的名称中。一般来说,如果您没有特定的搜索要求,我们建议您选择它。数据库(非全文搜索):上面使用的是全文搜索模式,但是全文搜索在使用 MySQL数据库 时作为Alist数据库会有一些奇怪的问题,暂时还未解决,所以如果你的Alist数据库更改为了 MySQL ,并且你的Alist版本≥3.9.1推荐你使用这个来构建索引,虽然比全文搜索慢一些差距不是很大,但是不会搜索出奇怪的文件,比较稳妥,等未来版本修复后再通知大家使用全新的全文搜索来构建索引,如果你使用的是 sqlite3 那两个你喜欢用那个都可以bleve:一个开源全文搜索引擎。它将分割对象名称中的单词,并搜索您输入的关键字。但它的搜索结果可能很奇怪,你不能得到你想要的结果,而且它会占用更多的资源。- sqlite3 容易触发
database is locked锁库无法写入文件 meilisearch:暂时未深度体验也不太了解具体差异,给予专业人士使用或者自己去查询一翻,查看PR链接,唯一知道的是得自己搭建使用,支持很多种方法,但是并没有守护进程等懒人操作、不支持系统依赖低于GLIBC_2.27以下的Linux系统、如果是本机搭建会自动识别,如果是其它设备可以修改配置文件的meilisearch字段内容- 守护进程:如果要使用可以自己按照手动启动OpenList的办法新建一个守护进程
- 下载地址:https://github.com/meilisearch/meilisearch/releases -
meilisearch文档地址:https://www.meilisearch.com/docs/learn/getting_started/installation - 参考链接:https://github.com/AlistGo/alist/discussions/6830
下表可以快速帮助您理解这两个搜索索引之间的区别:数据库(全文搜索) 数据库(非全文搜索) bleve meilisearch 搜索结果 中文基本上搜不到 比全文搜索准,可以搜索中文 模糊匹配 ❓ 搜索速度 快,优缺点看上面 比全文搜索慢,优缺点看上面 快 ❓ 指定文件夹搜索 支持 支持 不支持 ❓ 硬盘占用 低 低 高 ❓ 自动增量更新 支持 支持 不支持 ❓ WARNING注意
若你使用的是MySQL作为数据库,建议使用
非全文搜索(强烈推荐)非全文搜索虽然比不上全文搜索快,但是也慢不到哪里,若你非要使用全文搜索 可能得牺牲无法搜索中文为代价 若是使用 ==sqlite== 作为数据库,没有全文两个数据库随便选~ 全文搜索:不是在所有文件里面进行文件的文字里面进行搜索,别理解错了。
Search tips
搜索提示
- If you want to search for a specific folder, you must choose
databaseas the search index; - If you choose
databaseas the search index and the type of your database issqlite3, we suggest that you don’t make any changes in the admin page while building the index, as sqlite3 does not support concurrent writes and can causedatabase-lockissues; - If you choose
bleveas the search index, and if you want to search for new files or if you don’t want to search for deleted files, the index needs to be completely rebuilt to take effect becauseblevedoes not support incremental updates; - But for
database, it supports incremental updates, so you can search for new files or deleted files just by access the modified folder (and clickrefreshicon if cached) without rebuilding the index, which is much more convenient thanbleve.
- 如果你想搜索一个特定的文件夹,你必须选择
数据库作为搜索索引; - 如果你选择
数据库作为搜索索引,你的数据库类型是sqlite3,我们建议你在创建索引时不要在管理页面做任何更改,因为sqlite3不支持并发写,可能导致数据库锁定问题; - 如果你选择
bleve作为搜索索引,如果你想搜索新文件或不想搜索已删除的文件,索引需要完全重建才能生效,因为bleve不支持增量更新; - 但对于
数据库,它支持增量更新,所以你可以搜索新的文件或删除的文件,只需访问修改的文件夹(并单击’刷新’图标,如果缓存),无需重建索引,这比bleve方便得多。
Ignore paths
忽略路径
Paths to be skipped during index building, one path per line, multiple lines can be filled
- example:
- /aaa network disk
- /bbb network disk/ccc folder If you don’t want to configure this, you can turn on the
disable indexoption in each driver (≥3.42.0)
:::构建索引期间跳过填写的路径,一行一个路径,可多行填写
- 例子:
- /aaa网盘
- /bbb网盘/ccc文件夹 如果不想(不会)配置这里,可以去每个驱动中将
禁用索引选项打开(≥3.42.0)
:::
Update index
更新索引
- (formerly: the path to update the index) After building all the indexes, or a file has a large number of file updates, but it is inconvenient to rebuild, you can use this to update the index
- example: - /aaa network disk - /bbb network disk/ccc folder
- (原:要更新索引的路径) 构建完所有索引后,或者某文件有大批量文件更新,但是又不方便点重新构建就可以使用这个来更新一下索引
- 例子:
- /aaa网盘
- /bbb网盘/ccc文件夹
:::
Automatically update the index
自动更新索引
⚠️ The default is off, and the index will not be built automatically For example, you have already built the index, but added a network disk mount or folder update later But you have already built a lot of indexes. According to the previous words, there are two methods
- Go in folder by folder before building
- Or it is cumbersome to refactor all But this time, just turn on the
Automatically build indexbutton and enter the Newly mounted network disk or Updated folder, the indexed files in this directory and The folder automatically builds the index without entering a folder by folder to let him build it automatically
- Advantages: Don’t worry, all the indexes in this folder can be automatically built if there is an update into the root directory of the updated folder
- Cons: always on call ready to build
Someone will find out that [Path to update index](#Path to update index) can also be updated? Can be updated but the two do not conflict
- Automatically update index: suitable for users who build indexes for all files
- Update Index: Suitable for not to build indexes for all files, but there are files that need to be built, manually build indexes to avoid all being indexed
⚠️ 默认是关闭状态,不自动构建索引 例如你已经构建完毕索引,但是后面又添加一个 网盘挂载 或者 文件夹更新 但是你已经构建好了索引比较多按照以往的话两个办法
- 一个文件夹一个文件夹的进去然后才能构建
- 要么全部重构比较繁琐 但是这次只要把
自动构建索引按钮打开然后进入一下 新挂载的网盘 或者 有更新的文件夹 就会自动将这个目录里面索引的文件和文件夹自动构建索引不用一个文件夹一个文件夹的进入让他自动构建了
- 优点:不用操心,有更新进有更新的文件夹根目录即可自动构建这个文件夹内所有的索引
- 缺点:随时待命准备构建
有人会发现上面不是有 要更新索引的路径 也可以更新吗? 可以更新但是两者不冲突
Maximum index depth
最大索引深度
default 20. The one shown outside is built manually, and the update index option selects the depth in the update index button. Explanation: The directory can enter up to several layers. For example, if you have a folder with a depth of 30 layers, set it to 20, and only build the first 20 layers, and the remaining 10 layers will not be built.
默认为20。 外面显示的是手动构建的,更新索引选项在更新索引按钮里面选择深度。 说明:目录最多进几层,例如你有一个文件夹深度多达30层文件夹,设置为20,只构建前20层,剩下的10层不进行构建。
⚠️ Precautions for use
⚠️ 使用注意事项
- Alist V2 and v3 types of mounts cannot be built by default
- If you are using MySQL as the database, it is recommended that you use database (non-full-text search), Click to view details to see the second item
- In the future version (≥3.9.0 version), V3 users can choose whether to allow others to mount your network disk and then index it ⛔
Use with caution⛔- View details: https://alist.example.com/config/site.html#allow-indexing
- Don’t ask why V2 is not supported, because the V2 version is no longer maintained, so there is no follow-up
- Why not directly open V2 V3 index construction: https://github.com/alist-org/alist/discussions/2529
- After building an index, users without permissions can search for hidden file/folder solutions click to view
- Alist V2 和 v3 类型的挂载默认不能构建
- 如果你使用的是 MySQL 作为数据库,推荐你使用 数据库(非全文搜索), 点击查看详情看第二条
- 在未来版本(≥3.9.0版本)V3用户可以选择是否允许别人挂载你的网盘然后进行索引 ⛔
谨慎使用⛔- 详情查看:https://alist.example.com/zh/config/site.html#允许索引
- 别问为什么V2不支持,因为V2版本已不再进行维护,故没有后续了
- 为什么不直接开放V2 V3索引构建: https://github.com/alist-org/alist/discussions/2529
- 构建索引后,没有权限的用户可以搜索到隐藏的文件/文件夹解决方案点击查看
The database file is very large, what should I do if it is still the same after clearing the index?
数据库文件很大,清空索引后还是一样大怎么办?
Normal users do not modify the database options. They use the sqlite database to build indexes, which will cause the database file to be particularly large
- -Data files,
Datafolders in the same directory in Alist program,data.db,data.db-shm,data.db-walAfter turning on the constructive index, the more the number you build, the larger the files. Finally, you accidentally occupy the machine’s hard disk, and then click the clear index button. What should I do if the file is still as big? - This is caused by the cache of
sqlite, there are two solutions- We use commands or tools to connect to
sqlitedatabase, input:VACUUM;
bashVACUUM;- After using the command to clean up, we replace it with
mysqldatabase before constructing indexes - Sqlite replaced with mysql database tutorial:BV1iV4y1T7kh Comparison after cleaning the command: The picture above shows before cleaning up, and the following figure shows that after cleaning, you can execute several commands several times if there is no effect.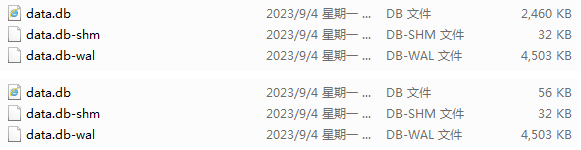
- We use commands or tools to connect to
data.db, data.db-shm, data.db-wal when backup, when backup,data.db-shm,data.db-walDo these two files need backup?
- In the backup, stop the program first, and then backup. You only need to backup the
data.dbdatabase file. The other two do not need to backup - It may be after you stop the program
data.db-shm,data.db-walwill automatically disappear, don’t worry
正常用户都是没有修改数据库选项使用的是 sqlite 数据库来构建索引的,就会导致数据库文件特别大
- 数据库文件在OpenList同级目录下的
data文件夹,data.db,data.db-shm,data.db-wal开启构建索引后,你构建的数量越多文件越大,最后不小心把机器的硬盘占满了,然后就点击了清除索引按钮,文件还是一样大这怎么办? - 这是因为
sqlite的缓存导致的(不知道对不对),我们后面有两种解决方案- 我们使用命令或者工具连接上
sqlite数据库,输入:VACUUM;
bashVACUUM;- 在使用命令清理后我们更换为
MySQL数据库后再来构建索引 - Sqlite如何更换为MySQL数据库教程:BV1iV4y1T7kh 使用命令清理前和使用命令清理后对比:上图为清理前,下图为清理后,如果没效果可以多执行几次命令。
- 我们使用命令或者工具连接上
data.db,data.db-shm,data.db-wal三个文件在备份时,data.db-shm,data.db-wal这两个文件是否需要备份
- 建议在备份时,先将程序停止,再进行备份,到时候可以只单独备份
data.db数据库文件,另外两个可以不进行备份 - 有可能在你停止程序后
data.db-shm,data.db-wal这两个文件会自动消失,也不用担心